在当今的数字化时代,数据的价值日益凸显。如何有效地提取并利用网上海量数据成为一个巨大的挑战,网络爬虫应运而生。网络爬虫(又被称为网页蜘蛛、网络机器人),是一种按照一定的规则,自动地抓取万维网网页数据的程序或者脚本。
可做爬虫的语言有PHP,JAVA,C#,C++,Python等,其中Python 爬虫备受关注,是因为Python程序相对来说比较简单,而且功能比较齐全。
晨域公司提供python爬虫爬取网页数据服务,可利用python爬虫将网站产品介绍、文章、图片、视频、文档等各种网页数据分类爬取下载下来。支持关键词采集,整站采集,类目采集,将网页数据内容进行过滤和整理后,可以excel、csv、mysql等客户要求的方式存储。并可利用批量去水印程序对网站图片水印进行快速去除,效果完好,不留痕迹。
如您需要python爬虫爬取网页数据服务,可与晨域公司联系,电话:13331218608,微信同号。

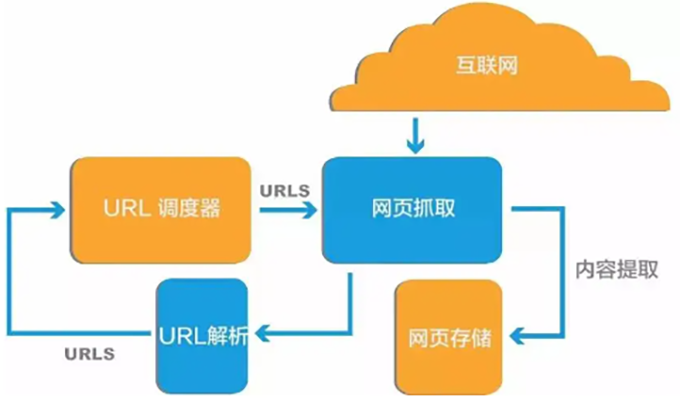
【python爬虫爬取网页数据流程】
发起HTTP请求:向目标网站发送请求。
解析HTML内容:用HTML解析库来解析返回的HTML内容。
提取所需数据:根据目标网页结构定位并提取特定信息。
处理和存储数据:将提取的数据进行清洗、转换后存储到数据库、文件或进行进一步分析。
【常用的python爬虫库】
BeautifulSoup是最常用的Python爬虫网页解析库之一,可将 HTML 和 XML 文档解析为树形结构,能更方便地识别和提取数据。
Requests:是 Python 爬虫中一个非常流行的第三方库,用于发送各种 HTTP 请求。它简化了 HTTP 请求的发送过程,使得从网页数据获取变得非常简单和直观。
urllib3: 是 Python爬虫内置网页请求库,类似于 Python 中的requests库,主要用于发送HTTP请求和处理HTTP响应。它建立在Python标准库的urllib模块之上,但提供了更高级别、更健壮的网页爬虫API。
Selenium 是一款基于浏览器地自动化程序库,可以爬取网页数据。它能在 JavaScript 渲染的网页上高效运行,这在其他 Python 爬虫库中并不多见。
Lxml:是一个功能强大且高效的Python爬虫库,主要用于处理XML和HTML文档。它提供了丰富的API,使得开发者可以轻松地读取、解析、创建和修改XML和HTML文档。
Scrapy是一个流行的高级Python爬虫框架,可快速高效地爬取网站并从其页面中提取结构化数据。



 :1299073570 网店:qushuiyin.taobao.com
:1299073570 网店:qushuiyin.taobao.com 


